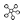
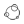传统基于忆阻器的神经网络加速器存在着大量的冗余模数转换。为解决该问题,中科院计算所副研究员、智源青年科学家陈晓明团队提出一种新的卷积神经网络数据流,将ReLU、max pooling置于模数转换之前,从而将模数转换代价降低到最小。为实现该数据流,提出基于忆阻器内容寻址存储器(RCAM)的非线性算子并行计算方法。由于RCAM阵列也可用于点积加速,提出了一个大规模可重构架构BRAHMS,该架构由一系列功能可配置的相同PE组成。每个PE可配置成点积、ReLU、max pooling、模数转换模式,同时通过配置数据通道实现数据的正确传输。跟已有的ISAAC架构相比,该团队的架构提升能效6.6倍。


图左:数据流 图右 功能可重构CNN加速器架构BRAHMS(图片来源:学者提供)